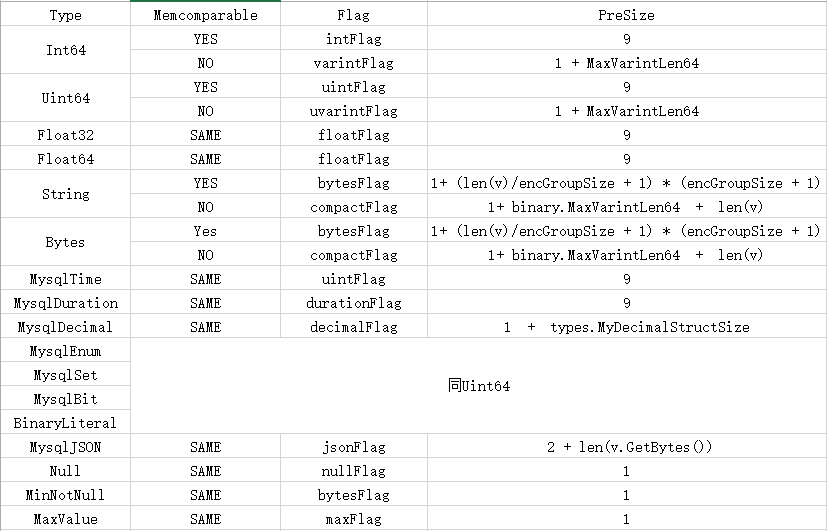
比如 select * from table1 where value < 15 这样一个查询, value的range就是[MinNotNull, 15). 对于这三个特殊值,并不依据具体的类型做编码,而是通过codeFlag这个字节来标识。结合key的编码比较方案,就可以实现对range边界的确定。
例如
1
selectfrom * from table2 where school <= "B"AND school isNotNull
// TypeCodeObject indicates the JSON is an object. TypeCodeObject TypeCode = 0x01 // TypeCodeArray indicates the JSON is an array. TypeCodeArray TypeCode = 0x03 // TypeCodeLiteral indicates the JSON is a literal. TypeCodeLiteral TypeCode = 0x04 // TypeCodeInt64 indicates the JSON is a signed integer. TypeCodeInt64 TypeCode = 0x09 // TypeCodeUint64 indicates the JSON is a unsigned integer. TypeCodeUint64 TypeCode = 0x0a // TypeCodeFloat64 indicates the JSON is a double float number. TypeCodeFloat64 TypeCode = 0x0b // TypeCodeString indicates the JSON is a string. TypeCodeString TypeCode = 0x0c
#!/bin/sh -e # # rc.local # # This script is executed at the end of each multiuser runlevel. # Make sure that the script will "exit 0" on success or any other # value on error. # # In order to enable or disable this script just change the execution # bits. # # By default this script does nothing. su -s /bin/sh sie -c"path_to_sp/connect.sh" exit 0
/usr/include/c++/5/typeinfo:39:37: error: expected ‘}’ before end of line /usr/include/c++/5/typeinfo:39:37: error: expected unqualified-id before end of line /usr/include/c++/5/typeinfo:39:37: error: expected ‘}’ before end of line /usr/include/c++/5/typeinfo:39:37: error: expected ‘}’ before end of line /usr/include/c++/5/typeinfo:39:37: error: expected ‘}’ before end of line /usr/include/c++/5/typeinfo:39:37: error: expected declaration before end of line Makefile:588: recipe for target ‘.build_release/src/caffe/proto/caffe.pb.o’ failed make: *** [.build_release/src/caffe/proto/caffe.pb.o] Error 1
# CUDA architecture setting: going with all of them.
# For CUDA < 6.0, comment the *_50 through *_61 lines for compatibility.
# For CUDA < 8.0, comment the *_60 and *_61 lines for compatibility.
# For CUDA >= 9.0, comment the *_20 and *_21 lines for compatibility.
CUDA_ARCH := -gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
-gencode arch=compute_60,code=sm_60 \
-gencode arch=compute_61,code=sm_61 \
-gencode arch=compute_61,code=compute_61
make runtest .build_release/tools/caffe: error while loading shared libraries: libopencv_imgcodecs.so.3.4: cannot open shared object file: No such file or directory Makefile:542: recipe for target ‘runtest’ failed
[libprotobuf ERROR google/protobuf/message_lite.cc:123] Can’t parse message of type “caffe.NetParameter” because it is missing required fields: layer[0].clip_param.min, layer[0].clip_param.max
import jieba import re import os # 导入停用词过滤表 stop_file_dir=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) STOP_WORDS = frozenset([line.strip() for line in open(os.path.join(stop_file_dir, 'stop.txt'),'r',encoding='gbk').readlines()])