TIDB基本类型的编码方案 TIDB在编码不同的数据类型时会在编码前部添加一个字节的Flag用来区分不同的编码方案。同时,TIDB支持具有Memcomparable特性的编码,Memcomparable是指保证编码前和编码后的比较关系不变。在TIDB中,对于Key的编码都是要求Memcomparable的,而对于Value的编码则不要求Memcomparable,可以采用更节省空间的编码方案。
在进行编码前,会先依据数据类型预先申请一定尺寸的byte,然后再进行编码。
如下是目前的Flag,用于标识不同的编码方案1 2 3 4 5 6 7 8 9 10 11 12 13 14 const ( NilFlag byte = 0 bytesFlag byte = 1 compactBytesFlag byte = 2 intFlag byte = 3 uintFlag byte = 4 floatFlag byte = 5 decimalFlag byte = 6 durationFlag byte = 7 varintFlag byte = 8 uvarintFlag byte = 9 jsonFlag byte = 10 maxFlag byte = 250 )
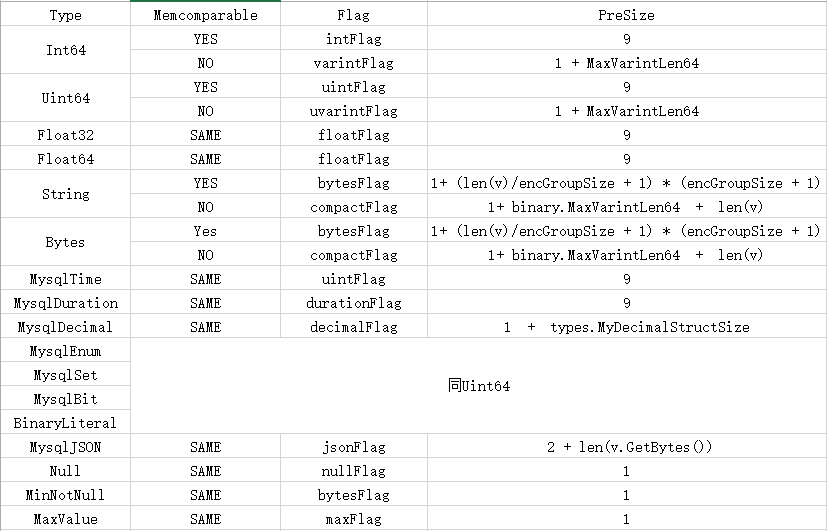
下表是数据类型与Flag的对应关系以及相应的编码尺寸计算方法,具体的编码方案会在后续一一展开。
INT64 comparable 这种方式保证编码后的二进制排序结果与编码前的是完全相同的。
编码方法: uint64(num) ^ signMask
const signMask uint64 = 0x8000000000000000
signed int
binary
after code
1
0000 0000 0000 0001
1000 0000 0000 0001
0
0000 0000 0000 0001
1000 0000 0000 0001
-1
1111 1111 1111 1111
0111 1111 1111 1111
-2
1111 1111 1111 1110
0111 1111 1111 1110
uncomparable: 这种方法不能保证编码后是严格有序的。
编码方法: PutVarint函数
PutVarint:
步骤一:左移去掉符号位,如果是负数则对移位后的数取反
步骤二:将得到的数字从低到高每七位放入一个字节中,字节的第一位表示是否有后续字节。
举例:
原始数据
16进制表示
步骤一结果
步骤二结果
1
0x1
0x02
0x02
-1
0xffffffffffffffff
0x01
0x01
128
0x80
0x0100
0x8002
127
0x7f
0xfe
0xfe01
Uint64 comparable 直接写入二进制
uncomparable 将二进制表示从低到高每七位放入一个字节中,字节的第一位表示是否有后续字节,其实就是去掉int64的uncomparable中符号处理那一步后剩下的步骤。
Float32 Float64 Go的浮点数是按照IEEE 754浮点数标准存储的,TIDB直接对二进制表示进行操作
将正浮点数的符号位置1,将负浮点数的二进制表示按位取反
这样编码后的二进制是先比较符号位,再比较指数位,最后比较小数位,就可以保证编码值是升序的。对于负浮点数的比较因为是进行了取反,所以也能保证是升序的。如果要降序只要将编码值取反即可。1 2 3 4 5 6 7 8 9 func encodeFloatToCmpUint64 (f float64 ) uint64 u := math.Float64bits(f) if f >= 0 { u |= signMask } else { u = ^u } return u }
Byte comparable [group1][marker1]…[groupN][markerN]
group 是补零之后的8字节切片
markder = 0xFF - 补零数量
举例:
[] -> [0, 0, 0, 0, 0, 0, 0, 0, 247]
[1, 2, 3] -> [1, 2, 3, 0, 0, 0, 0, 0, 250]
[1, 2, 3, 0] -> [1, 2, 3, 0, 0, 0, 0, 0, 251]
[1, 2, 3, 4, 5, 6, 7, 8] -> [1, 2, 3, 4, 5, 6, 7, 8, 255, 0, 0, 0, 0, 0, 0, 0, 0, 247]
uncomparable 数据长度 + 实际数据的二进制
String 如果有排序规则,则使用排序规则得到的Bytes,否则直接用String本身的Bytes1 2 3 4 5 6 func encodeString (b []byte , val types.Datum, comparable bool ) []byte if collate.NewCollationEnabled() && comparable { return encodeBytes(b, collate.GetCollator(val.Collation()).Key(val.GetString()), true ) } return encodeBytes(b, val.GetBytes(), comparable) }
MysqlTime 先进行时区转化,全部转换为UTC时区后将Time转为uint64,再以uint64的形式进行编码。
MysqlDuration duration可能有负值,所以无法直接用string来进行编码,采用的是同Int comparable相同的编码。
MysqlDecimal 编码方式: precision + frac + WriteBin函数
WriteBin: 每 9 位十进制数字包装成 4 个字节. 其中整数和小数部分分别确定所需的存储空间. 如果数字位数为 9 的倍数, 则每 9 位十进制数字各采用 4 个字节进行存储, 对于剩余不足 9 位的数字, 所需的存储空间如下表所示:
剩余数字位数
存储所需字节数
0
0
1-2
1
3-4
2
5-6
3
7-9
4
举例:
1234567890.1234
以9位数字以及小数点为边界,可将decimal类型拆分为如下所示:
1 234567890 123400000
假设存储位数为有效位数为14,小数位为4,使用16进制表示为三部分:
00-00-00-01 0D-FB-38-D2 07-5A-EF-40
现在,中间部分已经是被填满,它存储了9位的十进制数字:
............ 0D-FB-38-D2 ............
第一部分只有一个十进制数字,所以我们可以只用一个字节来存储,而不必浪费四个字节:
01 0D-FB-38-D2 ............
现在,最后一部分,它是123400000,我们可以用两个字节来存储:
01 0D-FB-38-D2 04-D2
因此,我们将一个12个字节的数字使用7字节进行了表示,现在需要将最高位反转来得到最后的结果:
81 0D FB 38 D2 04 D2
如果要表示 -1234567890.1234,需要将各个位取反:
7E F2 04 C7 2D FB 2D
最高位反转,是为了保证有相同有效位数和有效小数位的DECIMAL类型编码后的二进制具有comparable特性。原因如下:
首先,最高位的置不影响原先数值的表示,因为不管第一部分剩多少位数字,它永远不会取到最高位,所以正数的DECIMAL类型的comparable可以得到保证。
其次,通过最高位置1再反转的形式,可以保证所有的负数的二进制编码都小于正数的二进制编码,即保证了正数和负数二进制编码之间的comparable。
最后,负数编码的comparable则是通过将正数编码所有位取反保证的。
MysqlEnum MysqlSet MysqlBit BinaryLiteral 通过各自的ToNumber或者ToInt方法转化为uint64进行编码
MysqlJSON TypeCode + Value
TypeCode:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 TypeCodeObject TypeCode = 0x01 TypeCodeArray TypeCode = 0x03 TypeCodeLiteral TypeCode = 0x04 TypeCodeInt64 TypeCode = 0x09 TypeCodeUint64 TypeCode = 0x0a TypeCodeFloat64 TypeCode = 0x0b TypeCodeString TypeCode = 0x0c Value []byte
Null NilFlag
MinNotNull bytesFlag
MaxValue maxFlag
编码模块位置
util/codec
tablecodec
util/rowcodec